
강화(Reinforcement)는 시행착오(Trial & Error) 를 통해 학습하는 방법을 말한다. 강화학습은 이 강화를 기반으로 보상과 패널티를 통해 학습해 목표를 찾아가는 학습 방법론이다.
우선 강화학습에서 사용되는 용어를 정리해보자.
| 용어 | 의미 |
| 에이전트(Agent) | 결정을 내리고 행동하는 주체. 게임의 경우 메인 캐릭터 |
| 환경(Environment) | 에이전트가 결정을 내리고 행동하는 배경, 세계 |
| 상태(State) | 현재의 상황을 나타냄. 캐릭터의 위치나 점수 등 |
| 행동(Action) | 에이전트가 취할 수 있는 선택 |
| 보상(Reward) | 에이전트가 특정 행동을 취했을 때 받는 댓가 |
| 정책(Policy | 각 상태(State)에서 최적의 행동(Action)을 결정하는 전략. 이는 에이전트가 학습을 통해 최적화하고자하는 대상임. |
| 가치 함수(Value Function) | 각 상태(State)에서의 가치를 평가하여 정책을 업데이트 하는 데 사용됨. |
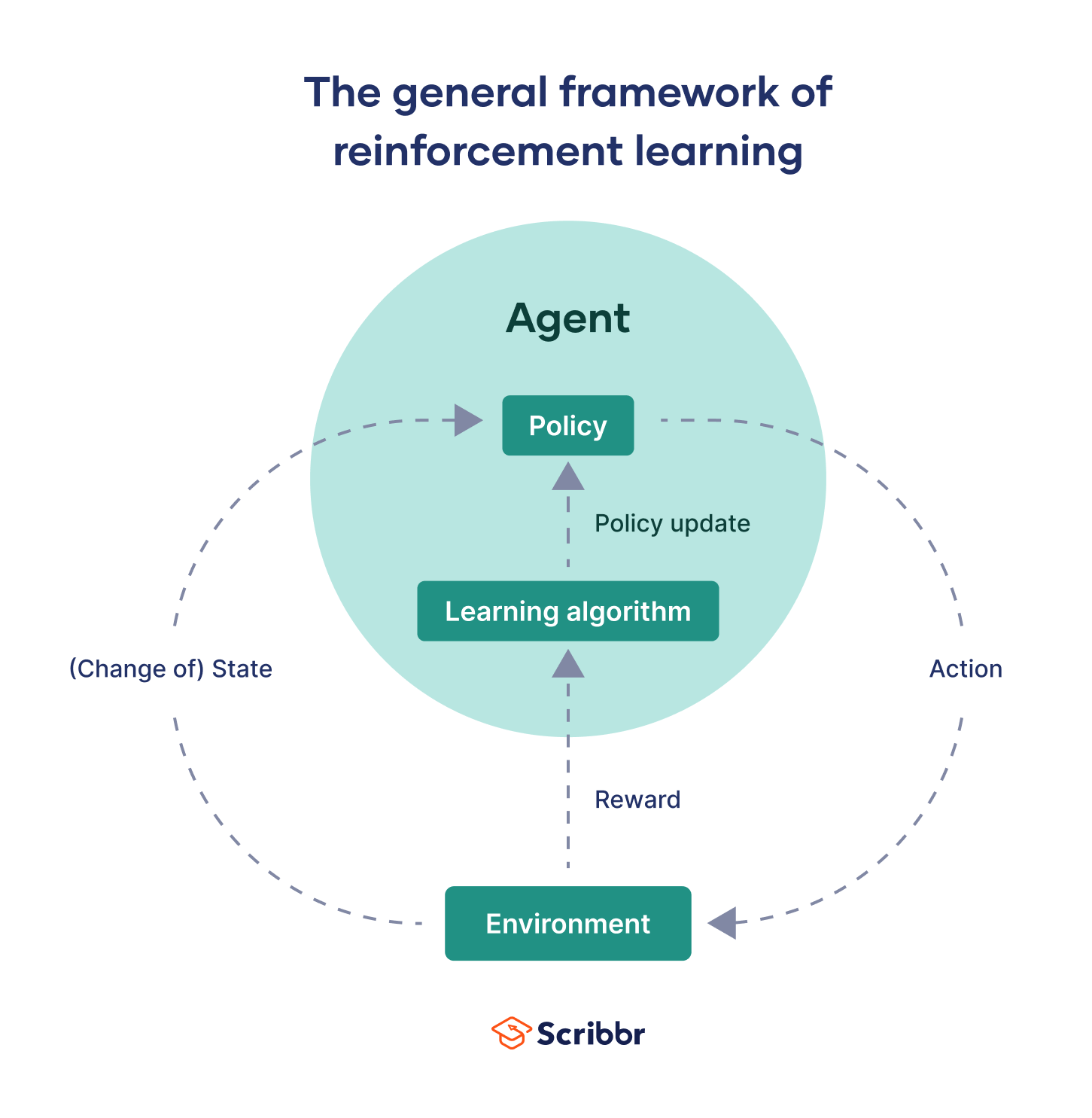
강화학습 알고리즘은 크게 두 가지로 구분할 수 있다.
Model-Based
- Environment에 대한 모든 설명을 알고 문제를 푸는 방법
- 핵심은 직접 행동을 하지 않고 최적의 솔루션을 찾을 수 있다는 것.
- 모델은 State와 Action을 받아서 다음 상태의 보상을 예측한다.
- 모델은 Planning에 사용되며 경험 전에 가능한 미래 상황을 고려해 행동을 예측한다.
- 모델과 Planning을 사용하여 해결하는 방식을 Model-based라고 함
Model-Free
- Model-based와 다르게 Environment를 모르는 상태에서 직접 수행하는 방식
- Agent가 행동을 통해 보상 합의 기댓값을 최대로 하는 Policy Function을 찾는 것
- 환경에 대해 알지 못하고 다음의 상태와 보상을 수동적으로 직접 행동하여 얻는다
- 환경 파악을 위해서 Exploration(탐사)을 한다.
- 탐사는 시행착오를 통해서 Policy Function을 점진적으로 학습시킨다.
'study > Reinforcement Learning' 카테고리의 다른 글
| [RL] DQN(Deep Q-Networks) (0) | 2024.08.08 |
|---|---|
| [RL] Q-Learning (0) | 2024.08.08 |
| [RL] On-Policy / Off-Policy Q-Learning, SARSA (0) | 2024.08.05 |
| [RL] MRP(Markov Reward Process) & MDP(Markov Decision Process) (0) | 2024.07.28 |